Table Of Content

Each oven run would have four loaves, but not necessarily two of each dough type. (The exact proportion would be chosen randomly.) You would have 5 oven runs for each temperature; this could help you to account for variability among same-temperature oven runs. At a high level, blocking is used when you are designing a randomized experiment to determine how one or more treatments affect a given outcome.
1.1 Power for completely randomized design
If you look at all possible combinations in each row, each treatment pair occurs only one time. Interpretation of the coefficients of the corresponding models, residualanalysis, etc. is done “as usual.” The only difference is that we do not test theblock factor for statistical significance, but for efficiency. I think most of the time it’s just a matter of convention, likely proper to each field. I think that in medical context, in a two factors anova one of the factors is almost always called "treatment" and the other "block". Identify potential factors that are not the primary focus of the study but could introduce variability. In the first example provided above, the sex of the patient would be a nuisance variable.
1 Powergain of blocking?
Can MANOVA be performed on data with RCBD? - ResearchGate
Can MANOVA be performed on data with RCBD?.
Posted: Thu, 09 May 2013 07:00:00 GMT [source]
In a completely randomized $2\times2$ factorial layout (no blocks), you would completely randomly decide the order in which the breads are baked. For each loaf, you would preheat the oven, open a package of bread dough, and bake it. This would involve running the oven 160 times, once for each loaf of bread. An alternate way of summarizing the design trials would be to use a 4x3 matrix whose 4 rows are the levels of the treatment X1 and whose columns are the 3 levels of the blocking variable X2. The cells in the matrix have indices that match the X1, X2 combinations above.
3 Paired Analysis

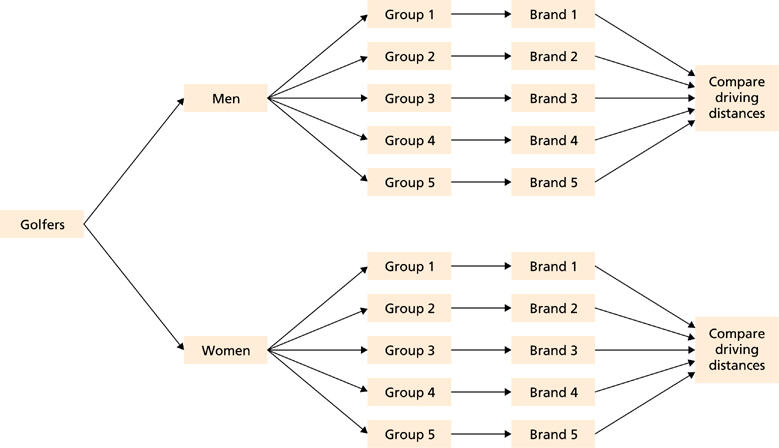
Here are some examples of what your blocking factor might look like. All variables which are not independent variables but could affect the results (DV) of the experiment. To assess the effect of the organization on recall, a researcher randomly assigned student volunteers to two conditions. Instead of a single treatment factor, we can also have a factorial treatmentstructure within every block.
Random Allocation
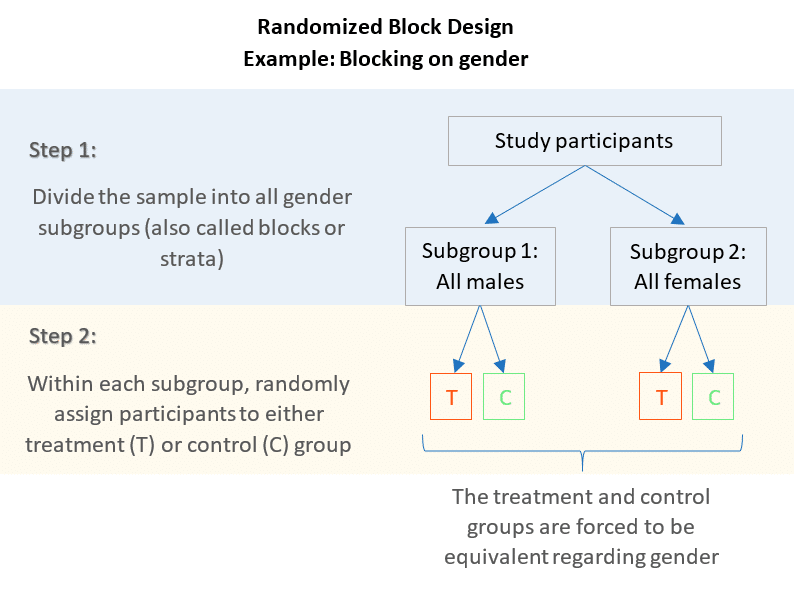
Blocking first, then randomizing ensures that the treatment and control group are balanced with regard to the variables blocked on. If you think a variable could influence the response, you should block on that variable. BlockingWith small samples, it's possible to randomly divide the subjects and still get different groups. In order to address this, researchers “block” subjects into relatively homogeneous groups first and then randomly decide within each block who becomes a part of the control group and who becomes a part of the treatment group.
Choose your blocking factor(s)
Suppose engineers at a semiconductor manufacturing facility want to test whether different wafer implant material dosages have a significant effect on resistivity measurements after a diffusion process taking place in a furnace. They have four different dosages they want to try and enough experimental wafers from the same lot to run three wafers at each of the dosages. As an example, imagine you were running a study to test two different brands of soccer cleats to determine whether soccer players run faster in one type of cleats or the other. Further, imagine that some of the soccer players you are testing your cleats on only have grass fields available to them and others only have artificial grass or turf fields available to them. Now, say you have reason to believe that athletes tend to run 10% faster on turf fields than grass fields. Switch them around...now first fit treatments and then the blocks.
The 7 deadly sins of research News - Nature.com
The 7 deadly sins of research News.
Posted: Tue, 10 Dec 2019 08:00:00 GMT [source]
How do you construct a BIBD?
Triangular (T) and semicircular (S) obstacles increased the performance significantly. Each manipulation on the traditional serpentine FF affected the power output positively, essentially. The pattern structures of the diagonal semicircle (DS) and diagonal triangular (DT) FFs reduced both water evacuation ability and performance increase rate.
It is good practice to write the block factor first; incase of unbalanced data, we would get the effect of variety adjusted for blockin the sequential type I output of summary, see Section 4.2.5and also Chapter 8. In Design of Experiments, blocking involves recognizing uncontrolled factors in an experiment–for example, gender and age in a medical study–and ensuring as wide a spread as possible across these nuisance factors. Let’s take participant gender in a simple 3-factor experiment as an example. The final step in the blocking process is allocating your observations into different treatment groups. All you have to do is go through your blocks one by one and randomly assign observations from each block to treatment groups in a way such that each treatment group gets a similar number of observations from each block. The first step of implementing blocking is deciding what variables you need to balance across your treatment groups.
For example, consider if the drug was a diet pill and the researchers wanted to test the effect of the diet pills on weight loss. The explanatory variable is the diet pill and the response variable is the amount of weight loss. Although the sex of the patient is not the main focus of the experiment—the effect of the drug is—it is possible that the sex of the individual will affect the amount of weight lost.
This is usually a constraint given from the experimental situation. And then, the researcher must decide how many blocks are needed to run and how many replicates that provides in order to achieve the precision or the power that you want for the test. Repeated Measures design is an experimental design where the same participants participate in each independent variable condition. This means that each experiment condition includes the same group of participants. By extension, note that the trials for any K-factor randomized block design are simply the cell indices of a k dimensional matrix. In our previous diet pills example, a blocking factor could be the sex of a patient.
For a complete block design, we would have each treatment occurring one time within each block, so all entries in this matrix would be 1's. For an incomplete block design, the incidence matrix would be 0's and 1's simply indicating whether or not that treatment occurs in that block. A special case is the so-calledLatin Square design where we have two blockfactors and one treatment factor having \(g\) levels each (yes, all of them!).Hence, this is a very restrictive assumption. In a Latin Square design, eachtreatment (Latin letters) appears exactly once in each row and once ineach column.
For example, if the study contains the place as a blocking factor, the results could be generalized for the places. A fertilizer producer can only claim that it is effective regardless of the climate conditions when it is tested in various climate conditions. In this case, you would run the oven 40 times, which might make data collection faster.
After that, we discuss when you should use blocking in your experimental design. Finally, we walk through the steps that you need to take in order to implement blocking in your own experimental design. When we have missing data, it affects the average of the remaining treatments in a row, i.e., when complete data does not exist for each row - this affects the means. When we have complete data the block effect and the column effects both drop out of the analysis since they are orthogonal. With missing data or IBDs that are not orthogonal, even BIBD where orthogonality does not exist, the analysis requires us to use GLM which codes the data like we did previously.